
Optimizing LLM performances with model quantization — PART 1
Introduction
At NORMA, we incorporate Large Language Models (LLMs) into several production data pipelines, utilizing them for tasks such as extraction and classification. Among these models is NuExtract1.5: a large language model (LLM) designed to transform complex information extracted from text into structured data in JSON format.
NuExtract1.5 is a multilingual model built on Phi-3.5-mini-instruct, optimized for processing long documents and extracting structured data in JSON format. It is fine-tuned for tasks like legal, financial, or technical text analysis, ensuring high accuracy across diverse industries.
Context
We initially ran the NuExtract1.5 model locally from a GitHub repository. However, we observed significant performance issues, particularly concerning response times. Each query took approximately 20 minutes to return a response, which was unacceptable for our production needs. The model’s 128k token context size is powerful but requires massive GPU memory — up to 1TB for large documents. To solve this, we could work with a sliding window approach that reduces memory usage to under 30GB for 10k tokens by reusing previous results. This technique allows the model to focus on different parts of the input sequence when making predictions. While this improves efficiency, it can slow performance for smaller windows.
To address this issue, we explored a lightweight solution using a quantized model, which significantly improved efficiency without compromising accuracy.
What is model quantization?
Model quantization is a technique used to optimize neural networks by reducing the precision of the model’s weights and activations. Instead of using 32-bit floating-point numbers (FP32), quantized models represent weights and activations in lower precision formats, such as 8-bit integers (INT8).
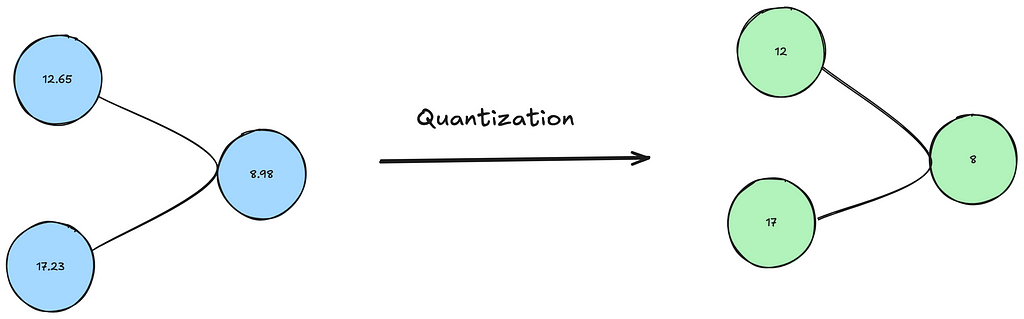
How does it works?
Weight Reduction: During the quantization process, the model’s weights are approximated and mapped to a smaller range of values. This reduces the size of the model on disk and in memory.
Inference Acceleration: Using INT8 or other smaller data types allows faster computations since modern hardware accelerators (e.g., GPUs, CPUs) can process lower-precision operations more efficiently.
Trade-offs: While quantization may lead to a slight loss in accuracy, the benefits in terms of reduced memory usage and faster inference times often outweigh this.
In the case of NuExtract1.5, we utilized its quantized version to achieve the desired trade-off.
How was it implemented?
To integrate the quantized model, we followed those steps:
- We selected the quantized version of NuExtract1.5, specifically the NuExtract-v1.5-Q4_K_M.gguf file, which uses GGUF format for quantized weights.
- We created an POST API endpoint using FastAPI to serve inference requests. The model was loaded using llama_cpp for inference.
- Loading the quantized model with llama_cpp library
app = FastAPI()
model_name = os.getenv("MODEL_NAME")
# Load model from HuggingFace
llm = Llama.from_pretrained(
repo_id="bartowski/NuExtract-v1.5-GGUF",
filename=model_name,
n_ctx=3900, # Context size
use_cache=True,
n_gpu_layers=n_gpu_layers # Offload this many layers to GPU if available
)
4. We wrote system prompts and user prompts to be passed to the chat completion in the main app function process_files().
5. The prompts are passed to the create_chat_completion() method of llama_cpp. The response from the model is parsed and returned in JSON format.
# Format the user prompt
user_prompt = USER_PROMPT_TEMPLATE.format(file_content=file_content)
formatted_prompt = f"<|system|> {SYSTEM_PROMPT}<|end|><|user|> {user_prompt}<|end|><|assistant|>"
# Send the prompt to the Llama model
try:
response = llm.create_chat_completion(
message=[
{"role": "user", "content": formatted_prompt}
],
max_tokens=512,
temperature=0,
stop=["<|end|>"]
)
logger.info("Model response: %s", response)
except Exception as model_error:
logger.error("Model inference failed: %s", model_error)
raise HTTPException(status_code=500, details=f"Model inference failed: {model_error}")
Deployment
We make a point of using a DevOps approach. A continuous deployment workflow has been defined in a .yaml file. After Dockerizing the application, it was deployed to Google Cloud Platform in an Artifact Registry, and its instance was reached from a Cloud Run url endpoint.
Here is a breakdown:
- Name the job and define first setup steps
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.12'
2. Install dependencies
- name: Install dependencies
run: |
python -m venv venv
source venv/bin/activate
python -m pip install --upgrade pip
pip install -r requirements.txt
3. Authenticate to your Google cloud account and setup the gcloud SDK
- id: 'auth'
name: 'Authenticate to Google Cloud'
uses: 'google-github-actions/auth@v2'
with:
credentials_json: ${{ secrets.GOOGLE_APPLICATION_CREDENTIALS }}
# Sets up the Google Cloud SDK, allowing subsequent commands to use gcloud
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v1
with:
export_default_credentials: true
- name: Install gcloud Beta Commands
run: gcloud components install beta --quiet
4. Configure Docker, build and push to Artifact Registry
- name: Configure Docker
run: gcloud auth configure-docker us-central1-docker.pkg.dev
- name: Build Docker Image
run: docker build -t us-central1-docker.pkg.dev/project-name/quantized-nuextract15-model/quantized-nuextract15:latest .
- name: Push Docker Image to Artifact Registry
run: docker push us-central1-docker.pkg.dev/project-name/quantized-nuextract15-model/quantized-nuextract15:latest
5. Setup and deploy the image to Cloud Run
- name: Deploy Nuextract Q4_K_M to Cloud Run (CPU)
run: |
gcloud run deploy quantized-nuextract15-q4-k-m \
--timeout=600 \
--region us-central1 \
--image us-central1-docker.pkg.dev/project-name/quantized-nuextract15-model/quantized-nuextract15:latest \
--ingress all \
--allow-unauthenticated \
--project project-name \
--cpu 8 \
--memory 32Gi \
--set-env-vars MODEL_NAME=NuExtract-v1.5-Q4_K_M.gguf \
--quiet
Conclusion
The quantized NuExtract1.5 model was executed on a MacBook with 16 GB of RAM. During execution, the process consumed approximately 2.73 GB of memory and ran on the CPU. Resulting in a significantly reduced response time from 20 minutes to about 2 minutes 30 seconds.
The lightweight GGUF format enabled efficient resource usage, while FastAPI streamlined deployment. This approach offers a scalable, performant, and easy-to-implement solution.

