
When I started this project, it was not an application. It was a single Python notebook.
At that time, the objective was straightforward: analyze media content using an AI model. The script would retrieve files stored locally on my machine (text, images, and other formats), process them sequentially, and produce results after a full batch execution. Technically, it worked.
It was a simple POC that needed to be quickly transformed as an industrialized product.
But there was a fundamental limitation: processing a complete dataset required approximately two hours and thirty minutes for a single dataset folder. Another goal was to turn this prototype into an application used by multiple users, which implied handling larger volumes of data.
That moment raised a simple but decisive question: what if this system needed to scale?
A functional but limited prototype

The original workflow followed a linear logic. Files were stored locally, accessed directly by the Python notebook, and processed one after another. The AI model would analyze each input and return a result, which was then aggregated at the end of the execution.
This approach was sufficient for experimentation. It allowed rapid iteration and validation of the core idea. However, its limitations quickly became apparent.
The entire process depended on a single machine. Execution time increased proportionally with the volume of data. There was no interface, no accessibility for other users, and no clear path to deployment. What existed at this stage was not a product, but a prototype: useful, but inherently constrained.
Rethinking the system: towards an AI serverless architecture

The architecture was redesigned to support scalability through a serverless approach. Computation is triggered on demand via API requests, without relying on a continuously running backend.
This shift enabled asynchronous parallelization at the media level. Using Python’s asyncio, each file is processed as an independent task, allowing multiple analyses to run concurrently. Processing time dropped from 2h30 for a full dataset to about 40 minutes, while infrastructure costs were reduced by eliminating the need for always-on virtual machines in favor of per-execution billing.
This model is particularly well suited for AI workloads, where processing is intensive but intermittent, and benefits from handling each input as an independent unit rather than a monolithic batch.
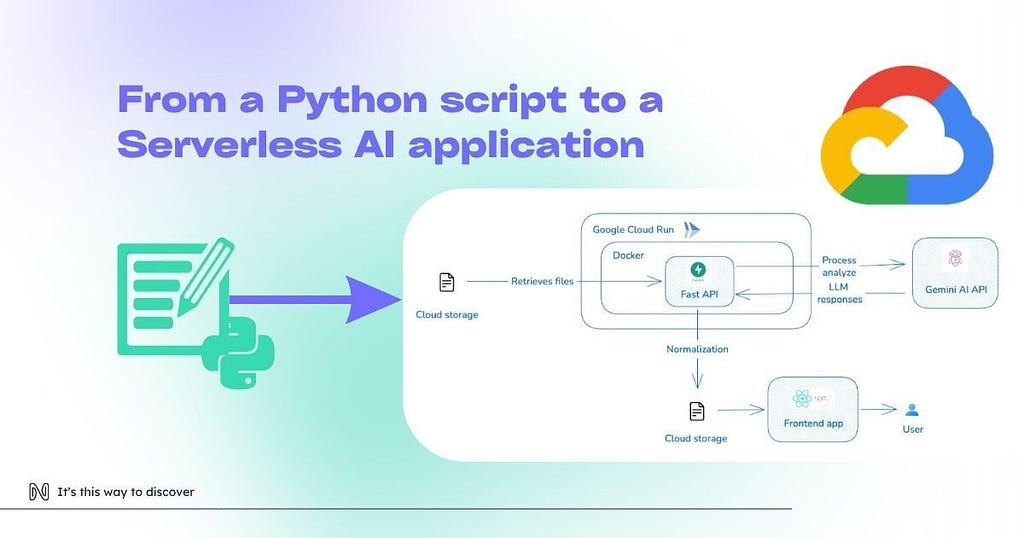
Designing the fullstack application
The frontend was developed using React and Next.js, providing an interface where users can retrieve media folders from their own Google Drive, trigger analysis and, at the end of the process, visualize structured results.
The backend evolved into a Fast API application, containing a set of analysis based on media type, written in Python. Each request triggers a new execution: from retrieving the Google Drive folder ID sent in the payload, accessing core data through Google auth permissions, handling the analysis of a single file or a small subset of data. This removes the need for a persistent server and allows the system to scale horizontally.
Once the analysis is done, the Gemini AI responses are normalized: it enforces structured responses, enabling downstream processing, validation, and a clear comprehension of the results from the frontend side.
Local outputs are replaced by Google Cloud Storage. Media files are no longer tied to a specific machine but stored remotely. This change was essential to make the system stateless and compatible with a distributed architecture.
A shift in execution model
The transformation of the system can be summarized by a change in how computation is approached.
Previously, the process was initiated manually through a command line execution. The system would run for hours before producing results.
In the new architecture, computation is event-driven. A user selects its Drive folder, which the ID is then sent in the API payload. This action triggers a serverless function, which calls the AI model and processes the content. Results are then returned within minutes, depending on the data volume in the input.
The difference is not only technical. It fundamentally changes the user experience, moving from delayed batch processing to near real-time interaction.
Challenges encountered during the transition
This transformation introduced several technical challenges, many of which are inherent to serverless and AI systems.
The first challenge concerned execution time. Serverless environments impose strict limits on how long a function can run. A process that originally required two and a half hours could not simply be migrated as is. The solution was to redesign the workflow by breaking it into smaller, independent tasks. Instead of processing an entire dataset in one run, each file is handled individually, allowing multiple executions to run in parallel.
File management also required a complete redesign. The original system relied entirely on local file paths, which are incompatible with distributed environments. Moving to Google Drive API and store results in Google Cloud Storage, made the system portable and stateless.
Another important challenge came from the nature of AI models themselves. Large language models, including Gemini, do not always produce deterministic outputs. This variability complicates integration into production systems. To address this, the application enforces structured outputs, validates responses, and applies normalization strategies when necessary.
Cost management became a new concern as well. Serverless architectures combined with AI APIs can scale rapidly, but this scalability comes with financial implications. Optimizing prompts, reducing unnecessary calls, and carefully controlling processing logic were essential to maintain efficiency.
Finally, performance considerations such as cold starts and API latency had to be addressed. Reducing payload sizes and simplifying function logic helped mitigate these issues and improve responsiveness.
Results and impact
The transition from a local notebook to a serverless application significantly transformed the system.
What previously required two hours and thirty minutes of batch processing can now be executed in near real time. The application is no longer limited to a single machine and can be accessed from anywhere. The architecture supports scalability, allowing multiple analyses to run concurrently without degrading performance.
Equally important, the system has become modular. Each component (frontend, backend, storage, and AI layer) can evolve independently, making it easier to extend and maintain.
Lessons learned
This project highlights a fundamental shift in how AI systems should be designed. Building a working script is only the first step. The real challenge lies in transforming that script into a system that can operate reliably at scale.
Serverless architectures provide a natural foundation for this transformation, but they also impose constraints that require careful design decisions. Perhaps the most important insight is that the complexity of AI applications does not come solely from the models themselves, but from the surrounding architecture.
Designing for scale forces a different way of thinking. It requires breaking down processes, managing uncertainty, and building systems that can adapt to variability.
Conclusion
What started as a local notebook evolved into a system designed to operate under real-world constraints: scalability, reliability, and performance. This shift required rethinking not only the technical stack, but also the way the problem itself was approached.
More importantly, it demonstrates that the value of an AI project is not defined by the model it uses, but by the system that makes it usable.
For anyone working on AI projects today, the challenge is clear. It is no longer enough to build scripts that work in isolation. The objective is to design systems that can scale, adapt, and deliver consistent value.

